












Do you want us to do proof of concept?
Want us to contact you?
Please send us your details, we will contact you shortly
Deepgreen DB is a scalable MPP data warehouse solution derived from the open source Greenplum Database Project. While maintaining 100% compatibility with the open source GPDB project, Deepgreen DB has a next-genaration query processor enhanced with (1) better join and aggregation algorithms, (2) new subsystem to handle spills, and (3) advanced techniques that maximize CPU performance through JIT-compiled query execution, vectorized scans, and data-path optimization.
Please send us your details, we will contact you shortly

a. Load Balancing
b. Data expansion
c. Data redistribution
d. Huge database (PetaByte Ready)
Xdrive is a Deepgreen DB connectivity service that extends the reach of Deepgreen to external data sources Through Xdrive.
Deepgreen DB is able to read/write from/to a myriad of data management systems, including Amazon S3, HDFS, Oracle, and Elastic Search.

Using Xdrive, Deepgreen DB is able to scan external tables at tremendous speed due to these underlying architectural choices:
All 22 queries of TPC-H are measured against Greenplum DB and Deepgreen DB. Q1 and Q5 are specifically graphed below for comparisons.
All Results
Q1: Scan and aggregate fact table
Q5: 6-way-join
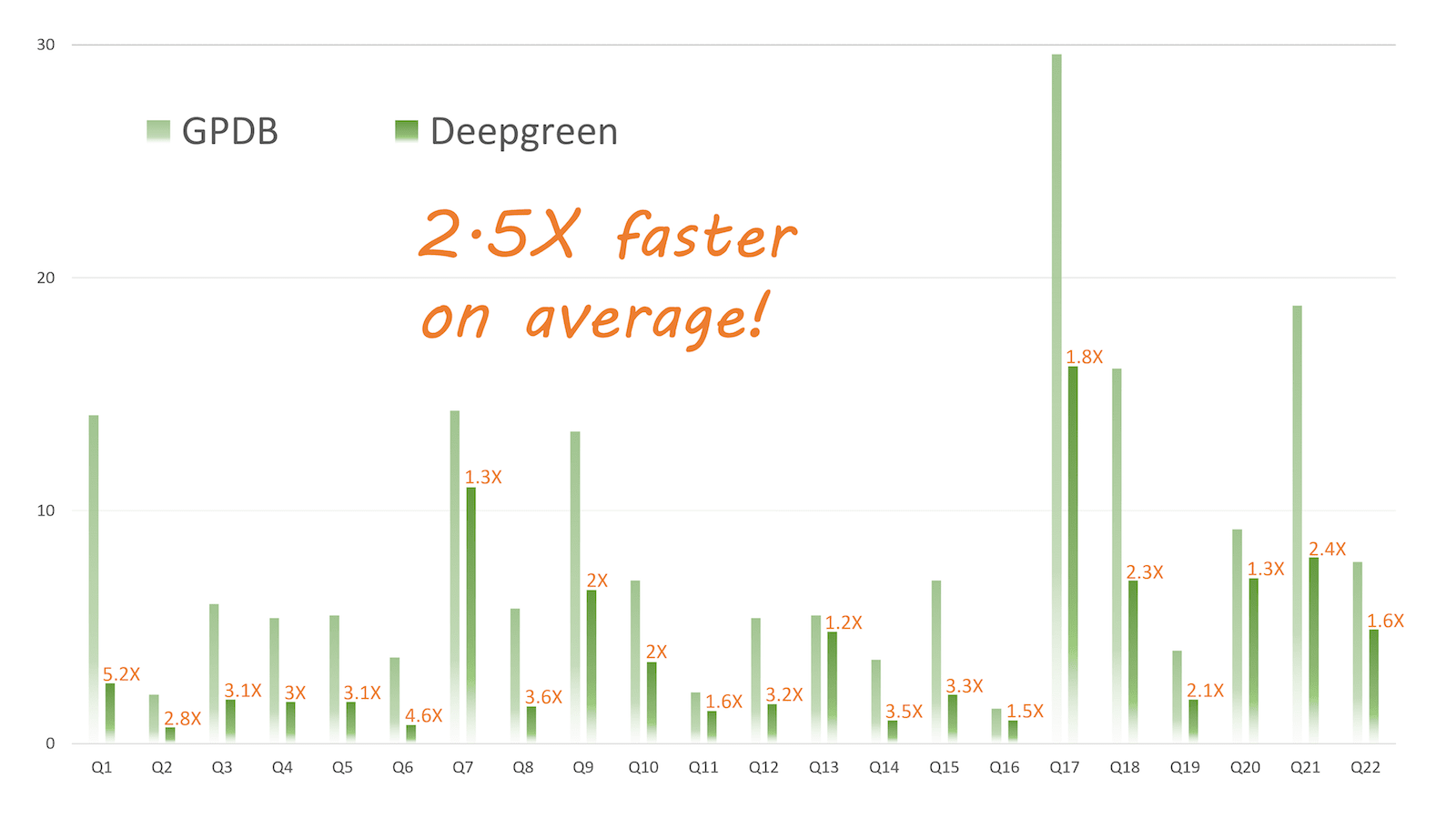
Raw result: Deepgreen DB vs Greenplum DB using Heap Tables
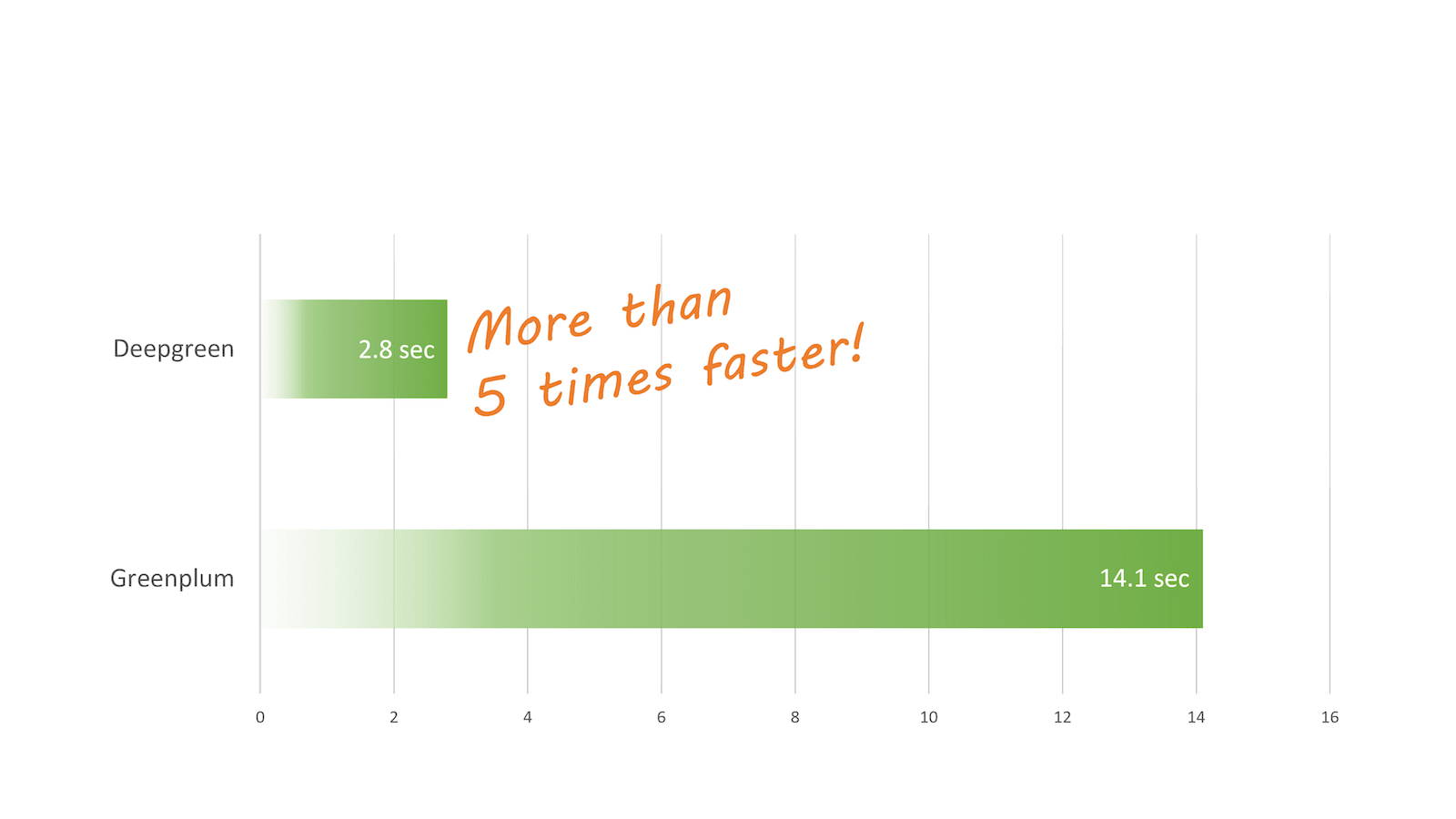
Q1 is a typical aggregate query running against the fact table.
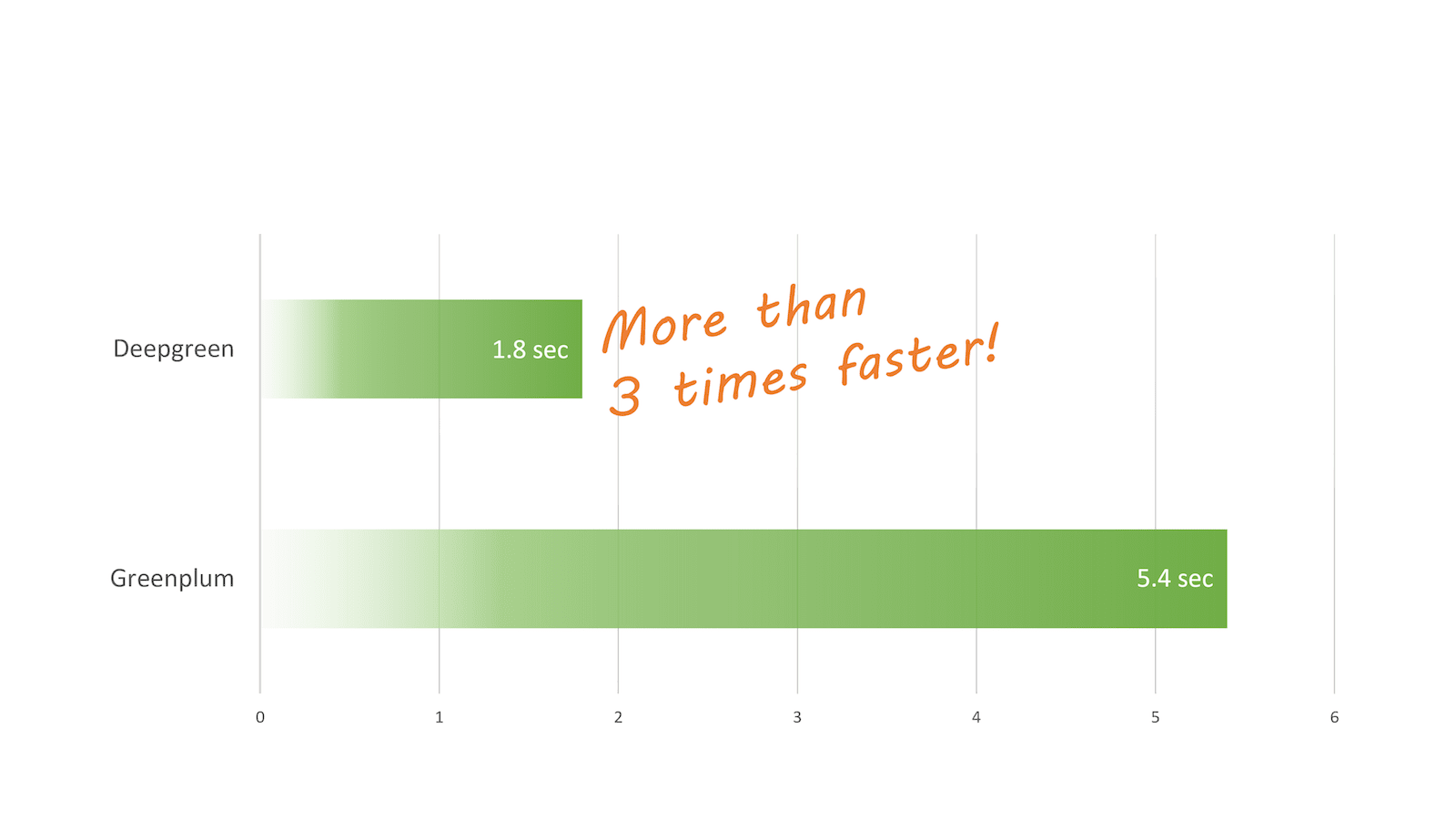
Q5 is an aggregate over a 6-way hashjoin that joins the fact table lineitem table against the orders and supplier tables, and subsequently against other dimension tables.
| Reporting Queries Comparison | |||||
|---|---|---|---|---|---|
| No | Query Report Name | Oracle(in minutes) | Deepgreen(in minutes) | Speed Gain | Total Row Count |
| 1 | flat_price | 85 | 2.8 | 21500% | 663,034 |
| 2 | sales_flyer_sli | 25 | 2.4 | 830% | 104 |
| 3 | profit_mtd_lost | 7.5 | 3.3 | 2121% | 383,359 |
| 4 | daily_lmi | 120 | 10 | 1200% | 154 |
| Deepgreen Server Hardware Specification | |
|---|---|
| Machine Type (HT) | Intel(R) Xeon(R) CPU E5-2643 @ 3.30GHz (16 HT) |
| RAM | 64 GB |
| Disk | PCI SSD NVMe Samsung Pro 960 2 TB |
| Kernel Version | Linux 3.16.0-8-amd64 |
| Operating System | Debian GNU/Linux 9 (stretch) |
| Oracle Data Source Server Hardware Specification | |
|---|---|
| Machine Type (HT) | Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz (48 HT) |
| RAM | 64 GB |
| Disk | SSD 2.7 TB |
| Kernel Version | Linux 3.10.0-514.10.2.el7.x86_64 |
| Operating System | Centos 7.3 |
| Reporting Queries Comparison | |||||
|---|---|---|---|---|---|
| No | Query Report Name | Oracle(in minutes) | Deepgreen(in minutes) | Speed Gain | Total Row Count |
| 1 | stok_teknisi | 37 | 4.8 | 770% | 408,122 |
| 2 | provisioning_v2 | 33 | 19.6 | 173% | 233,291 |
| 3 | kumulatif | 2 | 0.4 | 500% | 24,338 |
| 4 | out_project | 17 | 0.7 | 2420% | 465,676 |
| Deepgreen Server Hardware Specification | |
|---|---|
| Machine Type (HT) | AMD EPYC 7742 64-Core Processor (128 HT) |
| RAM | 128 GB |
| Disk | PCI SSD NVMe Samsung Pro 960 2 TB |
| Kernel Version | Linux 4.19.0-10-amd64 |
| Operating System | Debian GNU/Linux 10 (buster) |
Greenplum SQL
100%
Executor tuned for x86
5X Faster
AI & Machine Learning
TensorFlow, MADlib
Graph Processing
Pregel
Disaster Recovery
Non-stop & incremental
Column Store
PAX, GP-column-store
Compression
lz4, zstd, zlib, quicklz
Load & Connectivity
Xdrive, gpfdist, gpload
In-memory Data Grid
Xdrive-Geode
Stream Interface
Xdrive-Kafka
Fast Numerics
Dec64, Dec128
GUI Monitor
Zabbix, pgBadger
Text Search
Xdrive-Elastic-Search
Deepgreen DB is derived from the open source Greenplum DB project. It maintains 100% compatibility with Greenplum DB. From SQL and stored procedures syntax, to storage formats on disk, to operation utilities such as gpstart or gpfdist, Deepgreen DB ensures full compatibility to minimize effort in redeployment. In particular:
More Speed
For most OLAP workload that is CPU-bound, Deepgreen DB runs up to 3X faster than Greenplum DB on average.
More Connected
Using Xdrive, Deepgreen DB can read/write to/from many external data external sources in a distributed and efficient manner.
More Intelligent
Using the Transducer, Python and Go code fragments can be directly embedded into SQL to group and push data to TensorFlow for machine learning.
Please send us your details, we will contact you shortly